Architectural Issues in the HENP Grand Challenge Project
Summary by Arie Shoshani
Introduction
In the meeting that was held at LBNL on June 30th and July 31st, 1997, there were several issues that concerned the architecture of the system to support efficient analysis of the event data.
The main issues were:
Principles for the architecture design
There was agreement on several principles that guide the architecture design:
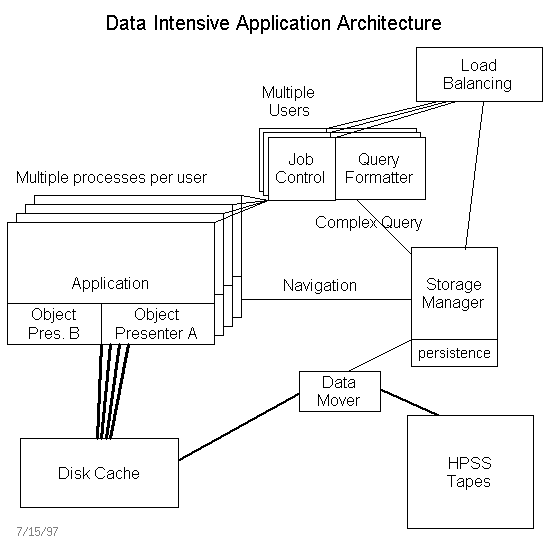
Architecture
According to the above principles, the architecture shown in figure 1 was adopted (it is an adaptation of an architecture diagram provided by Bill Johnston). It has the following main components. (i) An application environment that can support a variety of codes (including Fortran and C legacy codes). (ii) A storage manager whose responsibility is to keep track and manage the data on tape and on cache. (iii) A data mover that is responsible for moving the data from tape to disk cache according to instructions from the storage manager (currently, we assume it is the data mover of HPSS). (iv) The query formatter that interacts with user and programs to provide size and time estimates. (v) The job control module whose reponsibility is to look at the jobs requests from a global point of view and optimize the request stream to the storage manager.
Below is a more detailed discussion of each of these components and their functional requirements.
This is the environment where analysis programs
are launched. Since this environment needs to support legacy codes as well as new C++ codes, there are several "versions" for the support of the different programs, referred to as "object presenter 1", "object presenter 2", etc. Currently, we plan to use and extend the STAF facility.
2. The storage manager
There are two parts for the storage manager: the data loading part and the data access part.
The data loading part includes cluster analysis and data reorganization . The cluster analysis module responsibility is to identify the best way to cluster the event data. The data reorganization module is responsible for restructuring the event data according to the desired clustering.
The data access part is the one shown in figure 1, and it includes the exploration module and cache management. The exploration module provides size and time estimates for a given query. The cache management module determines which files to move from tape to the disk cache and in what order. The exploration module interacts with the query formatter, and the cache management module interacts with the job control module.
Hardware scenarios
We are proceeding with 2 scenarios in terms of where the disk cache should reside. In the first scenario the disk cache is a RAID under HPSS. 200GB of dedicated RAID will be provided to the GC experimental prototypes. The second scenario is an external cache (specifically DPSS) where the data mover under HPSS will be requested to stream the data to that cache.
The reason for the two scenarios is to learn the cost and efficiency tradeoffs of running a RAID under HPSS (providing about 50 MB/s per channel) and using an external distributed parallel cache that provides full control over the placement of the data.
Open issues
An open problem is the issue of data formats. The traditional legacy codes use a table format to represent the event and particle data. On the other hand, if one chooses some object-oriented database system (OODBMS) to manage the data, then the data needs to be loaded and stored by that system in its internal data formats (i.e. persistent C++ structures). These data formats will not work with legacy software. Similarly, if the data is stored in traditional table formats, they cannot be readily used by C++ programs. Since the data is too voluminous to store in both formats, it is necessary to make a choice of the primary format, and convert to the secondary format as needed by the analysis program.
The approach taken by STAR is leaning towards the second option, which is to store the data in table formats so that legacy software (currently about half a million lines of code in STAF) continues to work. For new C++ codes, the data will be loaded from the table formats into C++ structures. The C++ analysis program can then interact with an object-oriented database system to store the data they generate.
There is much interest in potentially using an OODBMS to store and manage the data on tertiary storage. The attraction in that is that C++ codes interact with this system, and have the flexibility to organize data (including clustering of objects) as is best for the analysis codes. In particular, the OODBMS Objectivity was chosen to be interfaced to HPSS, an approach that BABAR and other projects are pursuing.
There are several open issues with this approach. Essentially, it is necessary to have Objectivity perform all the functions currently planned for the storage manager. Below are the specifics.
Change log:
14 Oct 1997, remove a reference to add more material. D.O.