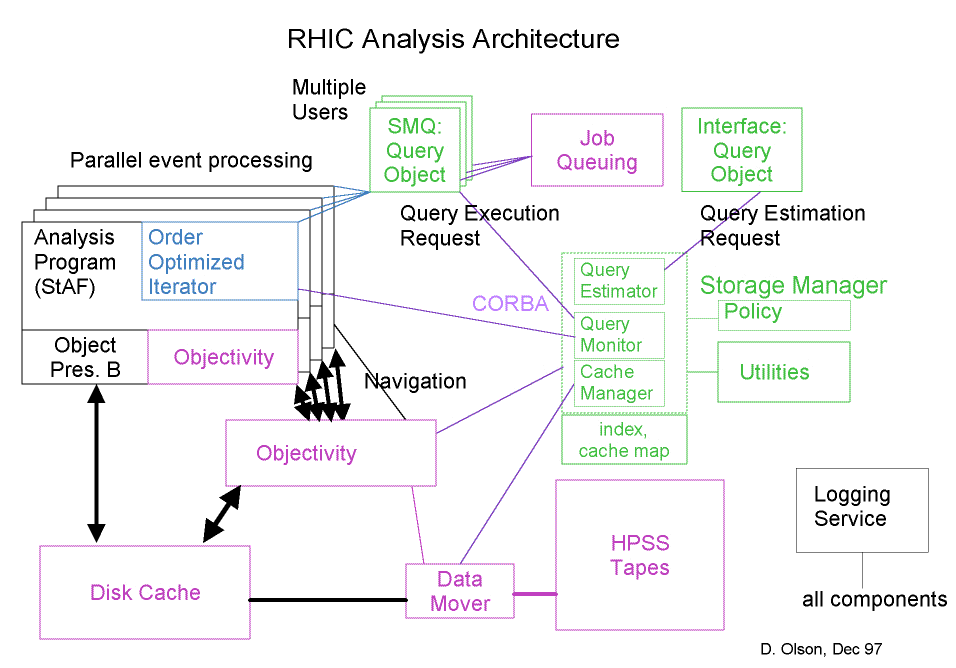
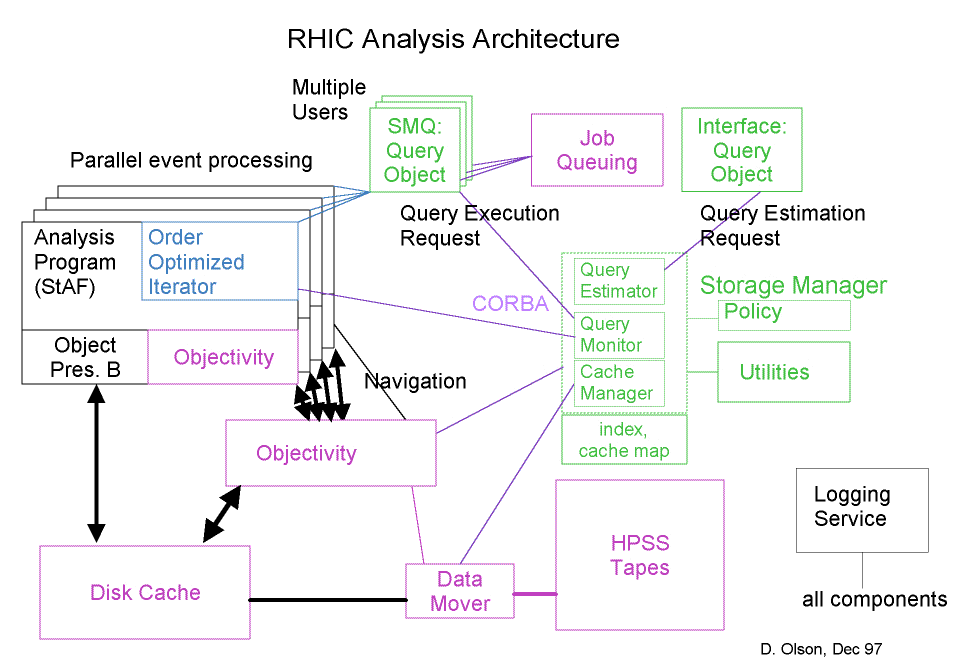
Software architecture for data mining and analysis.
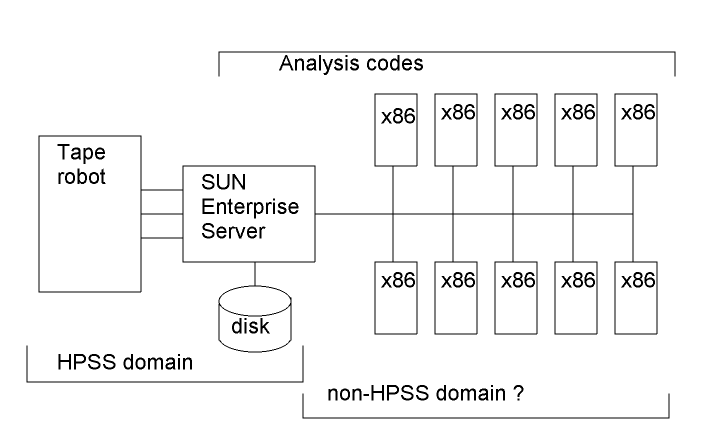
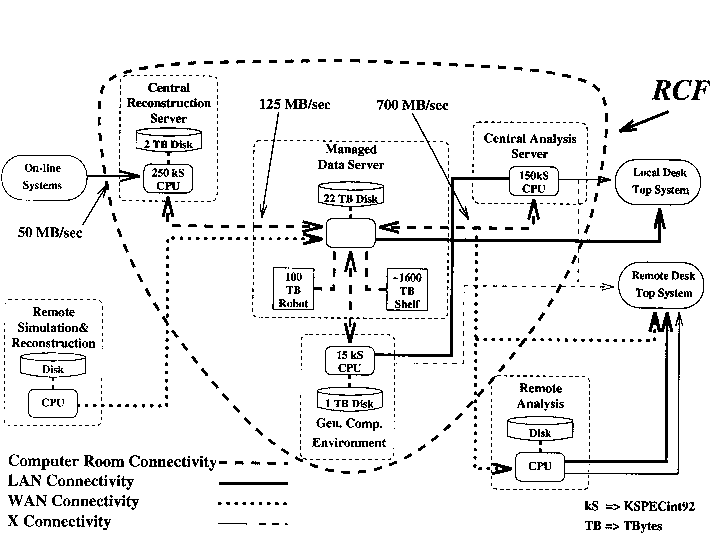
Simplified example of the analysis cpu-farm and data store.
(This is my sketch (D.O.), a better or different diagram is welcome.)
Updated: 05 May 1998 12:48
Introduction
Architecture and Overview
Description of Components
Query Estimator
Query Monitor
Cache Manager
Caching Policy
Clustering Analyzer
Tape Reorganizer
Storage Access Enhanced Iterator
Parallel Processing
Query Object
Queuing Service
CORBA Service
Logging Service
Tag Database
Storage System Simulator
Use Case (a query processing scenario)
Schedule
People
References
This document describes the features and components of the HENP grand challenge project being developed for the RHIC computing facility (RCF). In addition to the development aspects of this project there is effort being applied to generating simulated data by running physics event generators and (hopefully in the near future) detector simulations at NERSC. This program in generating simulated data is not described in this document.
The architecture is described along with an overview of the functionality of the software components, as well as the location within the RHIC Computing Facility (RCF) that the various components are expected to run. A schedule for which the functionality is expected to be available at the RCF is also listed with some milestones from the RCF plan and the experiments.
The diagrams below show the software architecture and a simplified view of the hardware layout being planned at the RCF upon which this software will run. An example of a data processing model that this architecture applies to is listed in the references.
Software architecture for data mining and analysis. |
Simplified example of the analysis cpu-farm and data store. (This is my sketch (D.O.), a better or different diagram is welcome.) |
| In the above diagram, the Storage Manager components and HPSS client software runs on the SUN Enterprise server. The disk cache is located on the SUN server. The analysis codes run both on the SUN server and on the Intel x86 CPU farm. |
The following diagram gives a data-flow view of the system.
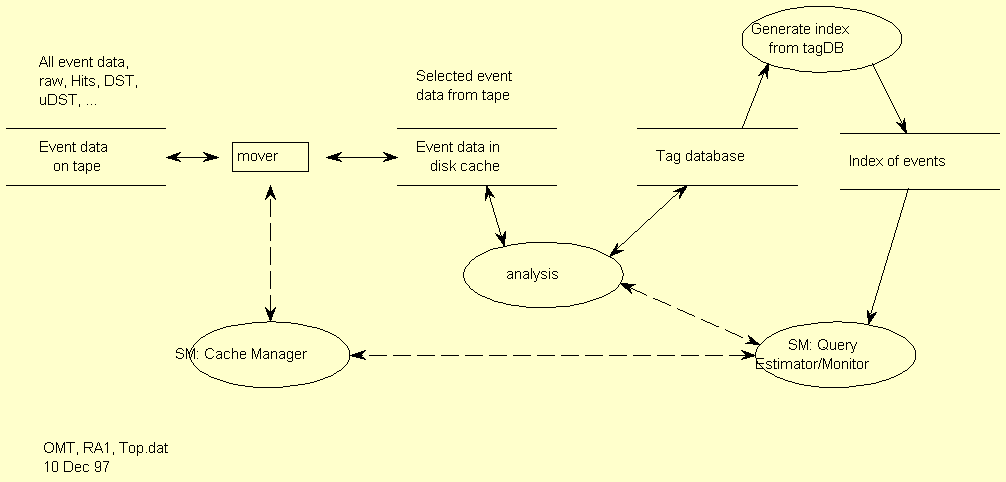 |
| Data flow view. |
In the components listed below some are essentially stand-alone services, such as the Query Estimator, while others are more like software libraries that provide a certain functionality, such as the logging service. A brief summary of each component is given here and the detailed descriptions follow.
| Component | Brief Description | Person(s) responsible | First delivery to RCF |
| Query Estimator | determines which events and files need to be accessed for each query request | A. Shoshani, H. Nordberg |
4/15/98 |
| Query Monitor | keeps track of which queries are executing at any time, what files are cached on behalf of each query, what files were purged but are still in cache, and what files still need to be cached | A. Shoshani, A. Sim |
4/15/98 |
| Cache manager | responsible for interfacing to HPSS to perform all the actions of staging and purging files from the disk cache. It keeps a queue of all request to cache and purge files, and executes them in order | A. Shoshani L. Bernardo |
4/15/98 |
| Caching Policy | selects which files to stage to disk cache from tertiary (tape) storage | A. Shoshani, A. Sim |
4/15/98 |
| Clustering Analyzer | facilitates the selection of properties to cluster on, and the binning strategy for each property | A. Shoshani, H. Nordberg, D. Rotem |
3/1/98 |
| Tape Reorganizer | responsible to reorganize the tapes according to the reordering specification generated by the Clustering Analyzer | A. Shoshani, L. Bernardo |
6/99 |
| Order Optimized Iterator | the means by which programs iterate over elements in a collection (events in an event list) | D. Malon | 4/15/98 |
| Parallel Event Processor | the toolset that makes parallel event processing possible by providing a means for identical code to run on multiple processors, with each process handling a disjoint subset of the data | D. Malon | 1/99 (?) |
| Query Object | the interface for query estimation and query execution | C. Tull | 4/15/98 |
| Queuing Service | processor farm job management system | R. Popescu | 3/1/98 |
| Corba | a standard software component that provides the ability to distribute objects on a network and to access those objects in a language and architecture neutral fashion | D. Stampf | 3/1/98 |
| Logging service | message logging service for accumulating monitoring information | C. Tull | 2/1/98 (?) |
| Tag database | (The master index to events.) | T. Wenaus, D. Morrison |
|
| Storage system simulator | MDSSim is a multi-threaded simulation of the RHIC MDS Architecture written in Java | D. Stampf | 1/1/98 |
| Object Manager | Objectivity under serious consideration | B. Gibbard | 9/1/97 |
| HPSS | High Performance Storage System software responsible for running tape robot | B. Gibbard | 5/1/98 |
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developer: Henrik Nordberg (hnordberg@lbl.gov)
Component Name: Query Estimator
Component Description:
The Query Estimator (QE) is one of three main components of the Storage Manager module (the Query Estimator, the Query Monitor, and the Cache Manager). It is responsible for determining, for each query request, which events and files need to be accessed. The QE has two main components: 1) The Index Constructor, and the Query Processor. The Index Constructor takes as input an "event table" (also referred to as n-tuple) and a "directory of files" and which event was assigned to which file, and generates the necessary indexes for determining which events qualify for a query. A specialized index (called a "compressed bit-sliced" index) is constructed to be used for quick (real-time) estimation of the number of events that qualify given a query. 2) The Query Processor is the component that uses the indexes to respond to various queries. All query requests from the Query Object are submitted to the QE. There are three types of queries:
- SELECT. This query type submits predicate conditions on the properties of the events (such as "number-of-pions > 2" AND 2<energy-level<5"). The QE uses its indexes to generate an event-OID set which is returned to the Query Object. We use the following notation for what is returned: {EID} - to denote set of event OIDs. A second SELECT query type submits either predicate conditions or an event-OID set {EID}, and one or more properties (P1, P2, …, Pn). The QE returns a set of tuples {(EID1, P11, P21, …, Pn1), (EID2, P12, P22, …, Pn2), …} for events that qualify.
- EXECUTE. This query type submits either predicate conditions or an event-OID set, and asks that the Storage Monitor will execute this request. The QE uses its indexes to generate a file-OID set {FID}, and for each file the event-OID set of events that qualify for this query. It passes this information to the Query Monitor (QM) along with the user-ID and query-ID. We use the following notation for what is passed to the QM: UID, QID {FID {EID}}.
- ESTIMATE. This query type submits either predicate conditions or an event-OID set. The QE returns to the Query Object estimate statistics. There are 2 levels of estimates, which we call ESTIMATE-QUICK, and ESTIMATE-FULL. For ESTIMATE-QUICK the QE uses in-memory indexes only to estimate the min-max number of events that qualify, the number of files that have to be cached, and the total MBs that have to cached. For ESTIMATE-FULL the QE uses secondary indexes (on disk) to determine the precise number of events that qualify, as well as the file statistics mentioned above. In addition, it provides the % of events that qualify in files, as well as a time estimate given what is in cache at that time.
Exceptions: The second type of the SELECT query will not be developed initially. It is planned for implementation at a later time.
Description of interfaces to other components:
The interface to the Query Object and the Query Monitor are via CORBA object defined in IDL.
Description of necessary external resources:
Compiler: Solaris C++
CORBA: Orbix or another ORB
Completion date estimate: April 15, 1998
Status on Jan 1st, 1998: design completed, implementation started
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developer: Alex Sim (asim@lbl.gov)
Component Name: Query Monitor
Component Description:
The Query Monitor (QM) is one of three main components of the Storage Manager module (the Query Estimator, the Query Monitor, and the Cache Manager). It is responsible for keeping track of which queries are executing at any time, what files are cached on behalf of each query, what files were purged but are still in cache, and what files still need to be cached. All the EXECUTE query requests that are submitted to the Query Estimator (QE) are passed to the QM for execution, after the QE uses its indexes to determine the set of files and event within each file that qualify for each query. We use the following notation for what the QE passes to the QM for each EXECUTE query request: UID, QID {FID {EID}}.
The model of interaction with Event Iterators (EIs) is as follows. The QM is designed to support multiple EIs per query. Each EI can request multiple files. Initially, it will be sufficient to support the special case is having a single EI that can request multiple files. However, the choice of launching multiple parallel EIs is supported as well. Files will be scheduled to be cached using an EI "pull" model. That is, a request for a file has to be made by an EI for the next file to be cached. Consequently, there may be several EI requests made on behalf of a single query.
The QM actions in response to a query execution request Q(i) are as follows. First, it adds the request to the end of query request queue. Then it checks if one or more EIs, EI(i,j) associated with for that query have been made. If so, it marks this query as "active", otherwise it is marked as "inactive".
When a query reaches the top of the queue, the QM checks if it is in "active" mode. If it is inactive, it puts it at the end of the queue. If it is active, it checks if the "cache full" flag is "full". If the cache if full, it goes to a wait-state. Otherwise, the QM sends a request to the Caching Policy (CP) module: "what file should be cached next?" The request may be denied by the CP module depending on the policy set (currently, the caching policy will deny a request if the total number of files cached (or scheduled to be cached) exceeds the maximum number (Qmax) set by the Caching Policy for the query. See CP module description for details).
If a response from the CP module is to cache a file FID, the QM sends a message to Cache Manager (CM). If CM responds that it can fulfill the request, it marks the file as "scheduled to be cached", otherwise it marks the "cache full" flag as "full". After the CM caches that file, it informs the QM, and the QM notifies the Event Iterator waiting for this file that the file was cached. It passes this Event Iterator the set of OIDs that qualify for its query, and moves this query to the end of the queue. In addition, it checks at this time if there are other "active" queries that can use the file just cached. If so, it notifies each that the file was cached, passes the set of OIDs that qualify, and moves the query to the end of the queue. The QM also handles exception conditions, for cases when the Event Iterators do not respond.
Each Event Iterator is expected to inform the QM when it is done with reading a file. Time-out mechanisms check that Event Iterators are alive, so that a file is not left in cache forever if an Event Iterator crashes or malfunctions. When a message from an Event Iterator gets to the QM saying that it is done with this file, the QM checks if other queries are using this file. If none, it marks the file for future removal, if necessary. (The reason that the QM marks this file for removal, but does not request the CM to purge it, is that it is not necessary to purge the file until the space is needed. Thus, in case that the same file is needed again, and it is still in cache it does not have to be re-staged). In addition, the QM marks the "cache full" flag as "not full" and schedules the query at the top of the queue to be serviced.
When the CP module determines which file to cache in response to the QM, it checks the available space on cache. If the space is less than the file size, it checks if there are files checked for removal. If so, it determines which file(s) to remove (see purging policy in the CP module). Thus, the response to the QM for a file to be cache next, may be preceded by one or more file purge requests. The query monitor passes the purge requests to the CM before the file caching request.
Description of interfaces to other components:
The interface to the Query Estimator, the Event Iterator, and the Cache Manager are via CORBA objects defined in IDL. The interface to the Policy Module is via in-process communication (this is because the Query Monitor and the Policy Module need access to the same data structures).
Description of necessary external resources:
Compiler: Solaris C++
CORBA: Orbix or another ORB
Completion date estimate: April 15, 1998
Status on Jan 1, 1998: design completed, implementation will start shortly
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developer: Luis Bernardo (LMBernardo@lbl.gov)
Component Name: Cache Manager
Component Description:
The Cache Manager (CM) is one of three main components of the Storage Manager module (the Query Estimator, the Query Monitor, and the Cache Manager). It is responsible for interfacing to HPSS to perform all the actions of staging and purging files from the disk cache. It keeps a queue of all request to cache and purge files, and executes them in order. When possible, it will schedule multiple file caching to be performed in parallel. It communicates only with HPSS and the QM. The following interactions between the QM and the CM exist.
- The QM requests a file (FID) to be staged. The CM responds immediately that the request has been scheduled, and adds the request to its queue.
- If HPSS is successful in staging a file, the CM notifies the QM that the file was staged. QM acknowledges, and takes action (see QM description).
- If HPSS is unsuccessful, the CM checks the reason for that. If the error is transient, it tries one more time. Otherwise, the CM notifies the QM that the file scheduled for staging cannot be staged. This action is needed in case of unexpected events, such as the loss of part of the cache, or if HPSS has modified its expected behavior because of competing requests. The QM acknowledges, and reschedules all queries for this file to be re-executed.
- The QM requests to purge a file. The CM acknowledges and executes the purge as soon as possible.
Description of interfaces to other components:
The interface of the cache manager to the Query Monitor is via CORBA objects defined in IDL.
Description of necessary external resources:
Compiler: Solaris C++
CORBA: Orbix or another ORB
Solaris HPSS client
Completion date estimate: April 15, 1998
Status on Jan 1, 1998: design completed, implementation will start shortly on RS6000
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developer: Alex Sim (asim@lbl.gov)
Component Name: Caching Policy
Component Description:
The Caching Policy (CP) module is a module which is invoked by the Query Monitor (QM). Its function is to select which files to stage to disk cache from tertiary (tape) storage.
The caching policy must take into account several considerations which may conflict. Some considerations are: i) favoring files that are requested by the larger number of queries; ii) servicing queries in the order they arrive, if no other priorities prevail; iii) making sure that some queries are not starved because of favoring other queries; iv) favoring queries that have a higher priority, etc.
The caching policy that will be used initially is intended to be simple, yet useful. As we gain experience the policy may change. The current policy is as follows:
- Service queries according to arrival time.
- There may be several EIs launched per query and several requests for file caching by each EI. The caching policy is to service one request form one EI per query, and then service the next query.
- The number of files cached per query (called Qmax) is a parameter that can be set. It is set to 2 by default. No EI will be serviced if the number of requests from all EIs exceed Qmax.
- The choice of which files to cache is made as follows: the file with the most events for the query being serviced will be favored. (An alternative may be to consider the number of queries that request the file. The file that is requested by the most queries will be cached first. However at this time, we do not choose to follow this policy.)
- After an EI is serviced, if the query associated with this EI still needs more files, the query is moved to the end of the queue. Otherwise, the query is considered completed.
- For an EI getting service (i.e. it is at the top of the queue), the policy module checks if any of the files requested are in cache. If so, it marks the file as used by this EI, and notifies the QM that this file is already in cache.
- If there are several files in the cache for a query (including files marked for removal), the files with the largest number of events that qualify for this query is selected.
- After the CP module determines which file to cache in response to the QM, it checks the available space on cache. If the space is less than the file size, it checks if there are files checked for removal. If so, it determines which file to remove. The current purging policy is to select the files that have the least numbers of queries potentially needing them. In case of a tie (e.g. all files have no potential queries needing them) we purge the file with the older time stamp first. (Note: the time stamp is when the file was not needed by any EI). Thus, the response to the QM for which file to cache next, may be preceded by one or more file purge requests.
Description of interfaces to other components:
The interface to the Query Monitor is via in-process communication. The messages sent are simply: "which file to cache next?" and the response is a file-ID, possibly null.
Description of necessary external resources:
Compiler: Solaris C++
CORBA: Orbix or another ORB
Completion date estimate: April 15, 1998
Status on Jan 1, 1998: design completed, implementation will start in February, 1998
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developers: Henrik Nordberg (hnordberg@lbl.gov) and Doron Rotem (D_Rotem@lbl.gov)
Component Name: Clustering Analyzer
Component Description:
The Clustering Analyzer (CA) is the module that facilitates the selection of properties to cluster on, and the binning strategy for each property. The input of this module is the file that contains the properties of each event (referred to as the n-tuple file). The analyst can specify any subset of the properties, and binning specification for each property. For this selection the CA generates a Lorenz distribution curve that shows the degree of clustering for this choice (it shows what percent of the cells fall into what percent of the cells). Using this tool the analyst can choose the properties and degree of binning to be used for re-clustering of the event order in files stored on tapes.
The CA has several components. 1) A web-based Property &Bin Specification tool for specifying the properties used for clustering analysis, and the bins selected for each property. The bins can be specified explicitly one by one, or by system computation. The choices for system computation are: "equal size" or "equal weight". "Equal value" generates bins of equal size (e.g. divide entire range to 10 equal bins), and "equal weight" determines the bin boundaries so that each bin contains the same number of events for this property. 2) A Distribution Analysis component that takes the property & bin specification and generates the Lorenz graphs. 3) A Cluster Determination component that takes the property & bin specification and generates clusters of cells for that property space. These clusters are displayed to the analyst for evaluation in a tabular form. 4) A Multi-Dimensional Linearization component that takes the clustering spec, and generates a liner order of the events to be stored in. It also organizes the events into files according to predicted optimal file size. The technique for the linear ordering is the Z-order methods applied to the multi-dimensional space of the properties. The Z-ordering has two levels: the z-order is applied per cluster, and the clusters themselves are stored in a Z-order according to their center of mass. This specification is the input to the Tape Reorganization module.
Exceptions: While the first three components of this module were already implemented, the last component, the Multi-Dimensional Linearization component, will not be implemented until we have some experience with large real datasets. We expect this to take place at the end of 1988.
Description of interfaces to other components:
The interface to the Tape Reoranization module and the Query Estimator is via files.
Description of necessary external resources:
Compiler: Solaris C++
Web tools: Visual Café, Netscape 4.04
Completion date estimate: March 1, 1998
Status on Jan 1st, 1998: design completed, implementation of components 1,2,3 completed. Interface between web-based tools and analysis components expected by March 1st.
Name of person responsible: Arie Shoshani (shoshani@lbl.gov)Name of developer: Luis Bernardo (LMBernardo@lbl.gov)
Component Name: Tape Reorganizer
Component Description:
The Tape Reorganizer (TR) is the component responsible to reorganize the tapes according to the reordering specification generated by the Clustering Analysis (QA) module. It has three main components. 1) The Reorganization Analyzer – the component that produces an execution plan to minimize the mounting of the tapes that need to be read and written into. 2) The Reorganization Monitor – the component that monitors the reading and writing of tapes by HPSS. Because the reorganization process may be very long (many hours) this module keeps track of the status of the reorganization (flow control), so that in case of a device or system failure, it can resume the operation from the last point of interruption.
3) The Directory Generator – the component that generates the directory of the order in which events were clustered into files. The directory contains one entry for each file that points to sections of an event table for the events in that file. The table has one row for each event, and represents the reorganized table of events and their properties that is generated by the event reconstruction process. This directory is the input for the Index Generator used by the Query Estimator.
Description of interfaces to other components:
The interface of the cache manager to the Query Monitor is via CORBA objects defined in IDL.
Description of necessary external resources:
Compiler: Solaris C++
Solaris HPSS client
Completion date estimate: April-June, 1999
Status on Jan 1, 1998: design will begin in July 1998, implementation will begin in October 1998.
Order Optimized Iterator
Name of person responsible:
David Malon
Name of component and description:
Order Optimized Iterator
The Order Optimized Iterator is the means by which programs iterate over elements in a collection. It has exactly the same interface as an ordinary iterator such as the template class d_Iterator<T> in ODMG 2.0. Only its implementation is different: it offers enhanced access to storage (hence the name) in that it returns elements in a retrieval order that has been optimized to account for physical clustering and caching on disk. Its intended use is as the mechanism by which physics codes iterate over events satisfying selection queries when those events must be retrieved from tertiary storage
Further comments on the d_Iterator interface appear in the Details section below. These ideas may evolve as the implications of adopting an STL approach become clearer.
For the iterator's role in the overall architecture, see
http://www-rnc.lbl.gov/GC/plan/rhic_arch.gif.
Description of interfaces to other components:
Iterator creation: Query execution triggers iterator creation. A natural way to do this might be for queries to have an execute(...) method that returns an iterator, but there are template-related technical difficulties associated with this approach. The ODMG 2.0 approach is to have a freestanding function
template <class T> void d_oql_execute(d_OQL_Query &q, d_Iterator<T> &results);
I propose that we support an equivalent strategy. We may also wish to support a query execute(...) method that returns a QueryToken that can, in turn, be used to initialize an iterator. More on QueryTokens appears in the section below. (Such an approach makes writing the freestanding execute method relatively easy, and provides a natural path to parallelism, but there are pros and cons.)
Interaction with Storage Manager: The minimal level of interaction required is equivalent to get_next_sublist() to provide the iterator with the next list of Ts (typically, d_Ref<Event>s or other EventIdentifiers) corresponding to data that have been cached by the Storage Manager. Since the Storage Manager will operate in a multiquery environment, probably the iterator will need to provide as input a QueryToken of some kind to identify which query's next sublist should be returned. The QueryToken may be opaque to the iterator. The form of the returned data requires some discussion; possibilities include a d_Collection<T> or sequence<T>; alternatively, iterator creation could provide, internal to the iterator seen by users, another (nested) iterator object whose next(...) method returns the next sublist.
(Note to self: check Arie/Craig document, and add reset(...) issues et al.)
STAF wrapper: A STAF wrapper for the iterator might have the same shape as the iterator itself, but, in the initial implementation, might be specifically an EventIterator (no templates--CORBA issues) whose next(...) method returns a tdmDataset* pointing to an Event dataset that has been built in transient memory, even if the underlying iterator were operating on d_Ref<Event>s.
Date of delivery:
April 15, 1998
Description of necessary external resources:
In addition to a template-capable C++ compiler and a reasonable object persistence system, the main external resource requirement is for whatever communications software will be used for messaging between the iterator and the Storage Manager.
Example:
gc_Query myQuery;gc_Iterator<EventId> myIterator;EventId thisEvent;...gc_query_execute(myQuery, myIterator);while (myIterator.next(thisEvent) {// do real work}
Details:
Put d_Iterator<T> interface issues here.
template class<T> class gc_Iterator<T> : public d_Iterator<T> { public: void initialize(QueryToken&); QueryToken& getQueryToken() const; };
Parallel Event Processor
Name of person responsible:
David Malon
Name of component and description:
Parallel Event Processor
The Parallel Event Processor may not be a component in the usual sense. It is the toolset that makes parallel event processing possible by providing a means for identical code to run on multiple processors, with each process handling a disjoint subset of the data. The mechanism for submitting parallel jobs may be external to software provided by the Grand Challenge. In an MPI (Message Passing Interface) environment, for example, one might submit a parallel job on P processors by executing
mpirun -np P programName arguments
The Parallel Event Processor toolset will attempt to shield the user from parallel programming details, but even if parallelism is transparent on the input side, it may need to be visible on the output side (e.g., when the user has P processes all trying to create and write to a single output file of his devising).
For the Parallel Event Processor toolset's role in the overall architecture, see
http://www-rnc.lbl.gov/GC/plan/rhic_arch.gif.
Description of interfaces to other components:
Iterator: The Parallel Event Processor toolset must be capable of initializing disjoint iterators operating on the same query results in parallel. Iterators should look no different in parallel and serial environments.
Interaction with Storage Manager: If the Storage Manager is designed to return the next sublist satisfying a particular query (identified, for example, by a QueryToken) to whomever asks for it, then parallelism should make no difference. (In more sophisticated incarnations, this may change.)
Date of delivery:
June 1999
Description of necessary external resources:
A parallel programming environment such as MPI is needed.
Example:
To a physicist, the parallelism could be transparent, and use the same code proposed in the serial iterator template:
gc_Query myQuery;gc_Iterator<EventId> myIterator;EventId thisEvent;...gc_query_execute(myQuery, myIterator);while (myIterator.next(thisEvent) {// do real work}There may be technical reasons to explicitly replace gc_query_execute with something like gc_parallel_query_execute.
Name of person responsible: Craig Tull
Name of developers: Craig Tull, Jeff Porter
Name of component: Query Object
Description:
The Query Object provides user access to the Storage Manager in order to:
a) Assess the system response to a particlar analysis job
Allow users to determine the extent of a potential analysis job over the full target data sample from either a selection on event properties or a list of event-Object IDentifiers. Results obtained from the Storage Manager for these assessment-type queries include the number of events which satisfy the query, estimates on real-time access to the selected data sample, and/or the list of event-Object IDentifiers associated with the property query for use in subsequent queries.
b) Execute pre-analysis configuration of the Storage Manager for an analysis job
Upon defining the extent of a job over the target data sample (as in a), execute the query to obtain access to the selected data sample via the Storage Manager's assignment of a QueryToken. All subsequent requests to the Storage Manager concerning the selected data sample (both job execution and status monitoring) are done via the QueryToken. The actual job-control functions which include execute/abort operations to the Storage Manager's file retrieval process can originate with the Query Object, however, it's role as a point-of-contact for the analysis control has not been fully developed.
c) Monitor the Storage Manager state for a particular job
Request information about the state of a given query operation (via the QueryToken) within the Storage Manager. The results reflect the cumulative status of the associated analysis from the viewpoint of the Storage Manager.
Within the standard GC architecture, http://www-rnc.lbl.gov/GC/plan/rhic_arch.gif, the primary function of the Query Object is to provide direct communication between the user and the Storage Manager via the Query Estimator process. As noted above, the additional job-control functions that are illustrated in the GC architecture have not been decided upon.
Description of interfaces to other components:
Interface to the Query Estimator via CORBA defined IDL. Interface to the user will eventually be via a StAF-ASP. Early implementation will not depend on StAF but has not been defined.
For a StAF-centric interface, see man page description for now.
Date of delivery:
April 15, 1998 for delivering basic functionality, without StAF-ASP wrapper or job-control definitions.
Desciption of necessary external resources:
C++ compiler, CORBA : Omnibroker or another ORB
Name of person responsible: Razvan Popescu
Name of component: Job Queuing (Nile)
Component Description:
Nile is a processor farm job management system designed to deal with a WAN distributed heterogeneous computing complex. We propose to evaluate it for use within RCF to manage local computing resources and to deploy it if appropriate as the Job Queuing system in which the Grand Challenge software would be run during the Mock Data Challenge in August 1998. The task involves getting the package to run on the RCF operating systems, perhaps involving a port to a not previously use operating system, and making such modifications to Nile as may be required to achieve compatibility with other components of the data access and processing systems at RCF. At this time the the fall back position in the event that this product turns our not to be usable, is the continued use of DQS.
Description of interfaces to other components:
Details of the interface are not at this time fully understood. The product must at minimum be able to evoke copies of the production executable, and must be able to receive estimates of data accessibility.
Date of delivery:
Initial tests: January 1, 1998
Prototype deployment : March 1, 1998
Production deployment : May 1, 1998Description of necessary external resources:
This product is being developed by Michael Ogg of the CLEO collaboration and is predicted to be available for first tests by the end of calendar 1997. Until this first version becomes available no tests are possible. While the author seems interested in supporting external use, the degree of support we will receive for problem we encounter is not known.
Name of person responsible: Dave Stampf
Name of component: Corba
Description:
Corba is a standard software component that provides the ability to distribute objects on a network and to access those objects in a language and architecture neutral fashion. Given our current choice of operating systems and architectures, we may install a free (for non commercial use) ORB on all computers in RHIC initially.
Description of interfaces to other components:
All software is free to take advantage of the existance of ORBs on every RHIC machine, but the programmer must be aware of programming in a generic fashion, not relying upon any custom features available from commercial ORB vendors.
Date of delivery:
Initial tests: ongoing
Prototype deployment : Jan 1, 1998
Production deployment : March 1, 1998Description of necessary external resources:
It is vital that we know of any requirements for Corba Services and CorbaFacilities that are required by any of the developers.
Name of person responsible: Craig Tull
Name of component: Logging Service
Description:
See this for now.
(should refer to the standard architecture diagram at http://www-rnc.lbl.gov/GC/plan/rhic_arch.gif).
Description of interfaces to other components:
(in as much detail as possible, missing details and needed definitions should be pointed out).
Date of delivery:
(date that software is to be installed and functional at the RCF. If a subset of the total functionality described above is to be delivered then this subset should be described).
Description of necessary external resources:
(should describe which other components are required, which compilers, additional software, OS, etc., and dates these resources are necessary in order to achieve the delivery date above.)
Name of persons responsible: Torre Wenaus, Dave Zimmerman (STAR)
Name of component and description: Tag database for STAR
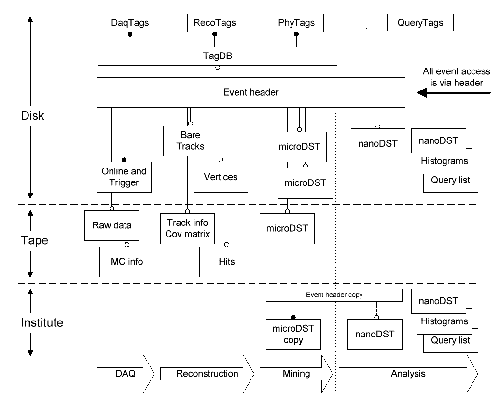
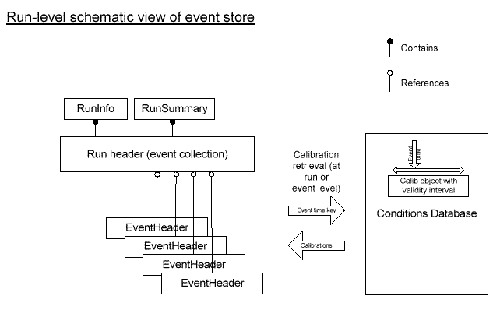
The tag database (TagDB) is a collection of event summary objects for each event that describe the most important event characteristics extracted from each stage of data processing. The tag database is extended at each stage of data processing through the addition of new TagDB objects, either new summaries or updates of existing ones. The TagDB objects for an event collectively provide fast access to the salient features of all aspects of the event from raw data (and Monte Carlo information for simulated events) to reconstruction and physics analysis. The tag database is compact and is stored on disk for fast access. The TagDB entries for an event are referenced from an event header object, which acts as a catalog and means of access for all components of the event. The TagDB is used in rapid scanning of events for quality assessment, summarizing the processing history, and most relevant to the Grand Challenge, building query indexes.
STAR Event Structure.
STAR Run structure in event store.
Example TagDB structure: - array of TagDB object references (VArray) hangs off the event header, or the event header has a reference to a TagDB header which internally has the array of TagDB object references - TagDB components and contents: - Raw data: - event time - event type - trigger mask - DAQ and online info - post-reconstruction (DST): - number of tracks (total and good) - number of clusters (total and good) - number of vertices - number of tracks associated with primary vertex - charge sum - average residuals - CPU times - total energy - mean pt - fraction of hits used in tracks - mean length of tracks - other QA info - particle type counts (loose cuts) - analysis-level (micro DST): TagDB will contain physics quantities agreed upon by the analysis groups, currently under discussionDescription of interfaces to other components:
Interface to storage manager: - TagDB provides to the storage manager (query index builder): - a list of parameters maintained in the TagDB that we wish to have the capability to query on (a subset of TagDB content) - access to the parameters themselves via the TagDB (via in turn the event header) for each event - an event identifier. The handle to the event header, as long as the design allows the event header OID to remain constant (otherwise a further level of abstraction needed). This is used to drive event retrieval for events meeting the query and give users (via the event iterator) access to retrieved events. - simple and effective implementation would be to just provide a pre-assembled array of query parameters (and an array of parameter names) for use by the query index builder. - Event list interface to the storage manager (query bypass) - query may be done by user code independent of the storage manager apparatus - in this case, what is provided to the storage manager is an event object list, not a database of event features to query on - note that the list provided is not an event list, but an event object list; it specifies what components of what events are required - the form of the list: - a list entry must have two components: - handle to the event header. By design, the event header handle will not change over time (at least under normal circumstances) - names of the desired event components; cannot use handles for these because these objects may be updated and/or moved, rendering previous handles obsolete - Multiple components for an event have to be retrieved together and provided to the user together - list could be VArray of handles to the events supplemented by the named components desired for each event - or integer-form OIDs, converted by the storage manager to handles, so that remote list-building software need not necessarily use Objectivity. Supplemented by the desired named components.Interface to event iterator: - Iterator returns to the analysis program the event header handle for an event matching the query, or on the list, with all required event components having been loaded to disk - in the STAF environment, the user's analysis code is invoked automatically for each retrieved event; the iterator apparatus is invisible to the user. The event component retrieval apparatus is also invisible; by the time the analysis code is invoked the needed event components have been loaded into their transient representations actually used by analysis code (eg. tables or physics analysis objects).Date of delivery:
March 1, 1998 - initial toy prototype - loaded from simu events - implementing the TagDB in the context of a top-level event headerApril 15, 1998 - MDC1 version prototype for testing and interfacing with the storage manager and some analysis code - provides interface agreed upon with the GC to make query index parameters availableJuly 15, 1998 - MDC1 final versionDescription of necessary external resources:
Objectivity on - NT VC++ 5 - Sun Solaris xx.xx
Name of person responsible:
(your name): Soren Sorensen
Name of component and description: PHENIX tag database
(should refer to the standard architecture diagram at http://www-rnc.lbl.gov/GC/plan/rhic_arch.gif).
Description of interfaces to other components:
(in as much detail as possible, missing details and needed definitions should be pointed out).
Date of delivery:
(date that software is to be installed and functional at the RCF. If a subset of the total functionality described above is to be delivered then this subset should be described).
Description of necessary external resources:
(should describe which other components are required, which compilers, additional software, OS, etc., and dates these resources are necessary in order to achieve the delivery date above.)
Name of person responsible: Dave Stampf
Name of component: MDSSim
Description:
MDSSim is a multi-threaded simulation of the RHIC MDS Architecture written in Java. It's purpose is to give a baseline indication of the expected performance and to provide a platform for quickly testing new management and flow algorithms.
Description of interfaces to other components:
MDSSim has recently been re-architected to more closely match the latest version of the architecture diagram. It should be a very close match in it's released version.
Date of delivery:
Initial tests: November 1997
Prototype deployment : Jan 1, 1998
Production deployment : Feb 1, 1998Description of necessary external resources:
None (JDK1.1?)
A Simple Use Case(as discussed in HENP Grand Challenge teleconference, 11 December 1997)Assumptions:- User begins with a selection criterion expressed as a query string; - user has an analysis code that takes an Event (or persistent pointer to Event) as input; - user intends to iterate over each event satisfying the selection criterionClient code:CAVEAT: Because of the various ways our components have been defined to date, this is pseudocode, a queer admixture of STAF instantiations, IDL, and C++. If you cannot follow it, let me know.//Step 1: smqQueryI* myQuery = smqFactory::newQuery("Query A", "attr1 > a AND attr2 <= b");/***************************************** begin optional stuff//Step 2 (optional): myQuery->doQuickEstimate(); if (myQuery->minNumEvents > cutoff) doSomethingElse();//Step 3 (optional): myQUery->doFullEstimate(); if ((myQuery->numEvents > tooMany) || (myQuery->numSeconds < tooLong)) doSomethingElse();end optional stuff *****************************************///Step 4. myQuery->execute();//Step 5. EventIterator* myIter = EventIteratorFactory::create(myQuery->token);d_Ref<Event> thisEvent; // or whatever the proper pointer representation is// Step 6. while (myIter->next(thisEvent)) { // ... physics analysis goes here }// user should probably free the iterator and the query object hereEnd Client CodeDetails:1. User invokes Query Factory's newquery method with a query string ("where" clause) to create a Query Object:smqQueryI smqFactoryI::newQuery(in string name, in string clause)Factory may talk to Storage Manager at this point, but it's not necessary.At this point, query attributes may be indeterminate.2. (Optional) User does quick estimate (smqQueryI::doQuickEstimate)2.1 Query Object invokes Query Estimator's ESTIMATE-QUICK method. 2.1.1 Query Estimator consults in-memory index to determine min/max number of qualifying events (bin boundary resolution), min/max number of files, min/max number of total MB. NOTE: Not all of these are reflected yet in the QueryObject interface. What about time (min/max time estimates)? These values are set in the calling Query Object (smqInquisitorI interface).3. (Optional) User does detailed estimate (smqQueryI::doFullEstimate)3.1 Query Object invokes Query Estimator's ESTIMATE-FULL method. 3.1.1 Query Estimator consults disk-resident database to determine exact number of qualifying events, number of files, number of total MB, estimated time to deliver all of the data, and percentage of events in files that must be cached that satisfy the query. NOTE: Not all of these are reflected yet in the QueryObject interface. These values are set in the calling Query Object (smqInquisitorI interface).4. User executes query (smqQueryI::execute(). Upon return, the Query Object's QueryToken (readonly attribute smqQueryI::token) is guaranteed to be valid. 4.1 Query Object invokes Query Estimator's EXECUTE method. 4.1.1 Query Estimator assigns a QueryToken (query id) to this query if it does not already have one, and sets the token attribute of the Query Object. 4.1.2 Query Estimator builds a file-OID set corresponding to all files and EventIds that satisfy the query. This work may already have been done as as part of an ESTIMATE-FULL request or (not discussed in this use case) a SELECT request. NOTE: Does the Query Estimator internally save things like the OID list after an ESTIMATE request, but before an execution request (that may never come)? If so, something like the Query Token should probably be assigned by whatever Query Estimator method is invoked first by the Query Object. How does it decide when it can delete such information? 4.1.3 Query Estimator invokes Query Monitor's EXECUTE method with user id, QueryToken, and file/event-id list. 4.1.3.1 Query Monitor adds query request to query request queue. 4.1.3.2 ... add internal details here ... 4.1.4 Query Estimator sets attributes like numEvents in the Query Object, and sets the token if necessary.5. User passes Query Object's Query Token to IteratorFactory, which returns an EventIterator:EventIterator* myIter = EventIteratorFactory::create(myQuery->token);6. User successively invokes EventIterator's next(...) method to return events satisfying the selection criterion.d_Ref<Event> thisEvent;while (myIter->next(thisEvent)) { ... }6.1 (Crude implementation)Before first invocation: Event Iterator's locally resident sublist is uninitialized, and hence exhausted in the cases considered below.6.1 CASE A: If currently resident sublist is exhausted: 6.1.1 (likely) Iterator notifies Query Monitor that file corresponding to the current sublist can be released. 6.1.1.1 Query Monitor decrements reference count to this cached file; when count reaches zero, QM notifies Cache Manager that file can be purged. 6.1.2 (necessary) Iterator invokes the QueryMonitor's getNextSublist method to get a new sublist, passing the QueryToken as a parameter. If the returned sublist is non-null, then Iterator sets thisEvent to point to the first element on the list and returns TRUE. If the returned sublist is null, there are no events to process and the iterator returns FALSE (breaking out of the user's WHILE loop). 6.1.2.1 Query Monitor returns a sublist of EventIds corresponding to a cached file needed by this query (identified by QueryToken), or a null sublist if no more events satisfy the query. If no additional files needed by the query have been cached yet, Query Monitor may simply force the Iterator to wait, or may return a status code with a promise to call back when a file is available (we have not yet decided). No extra Cache Manager requests are needed; the query is already on the caching queue as a result of the EXECUTE request. NOTE: If a query is waiting with nothing to do, might we want some internal Storage Manager interactions with the Policy Module to increase the priority of the query?CASE B: If currently resident sublist contains unused elements: next(...) sets thisEvent to point to the next element of the resident sublist, and returns TRUE.NOTE: A smarter implementation might request the next sublist before the current one is exhausted.David Malon 12 December 1997
4 Jan 98 version.
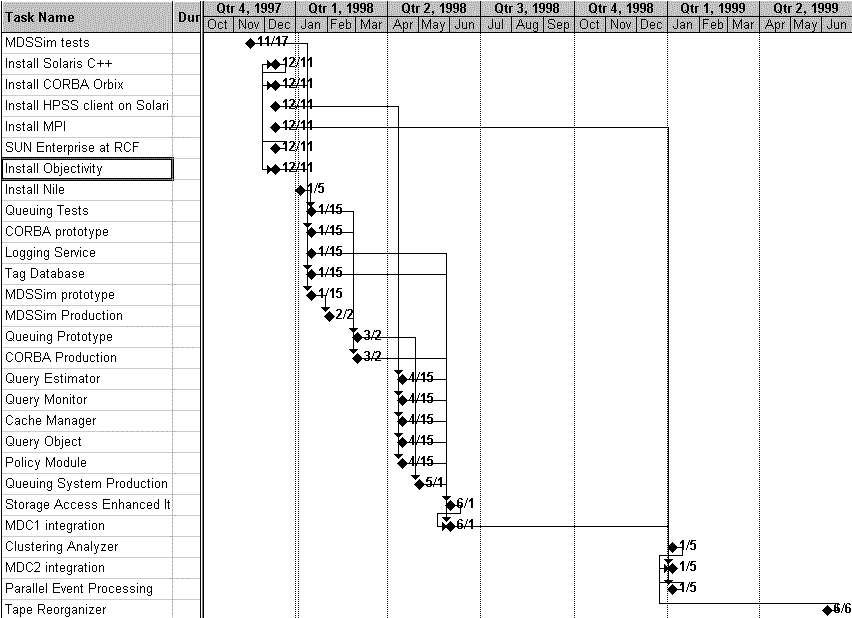
The people responsible for various software components are listed in the table below.
| Person(s) responsible | Components |
| H. Nordberg (LBNL) | Query Estimator, Clustering Analyzer |
| A. Sim (LBNL) | Query Monitor, Caching Policy |
| L. Bernardo (LBNL) | Cache manager, Tape Reorganizer |
| D. Rotem (LBNL) | Clustering Analyzer |
| A. Shoshani (LBNL) | Query Estimator, Query Monitor, Cache Manager, Clustering Analyzer, Tape Reorganizer |
| D. Malon (ANL) | Order Optimized Iterator, Parallel Event Processor, software integration |
| C. Tull (LBNL) | Query Object |
| R. Popescu (BNL) | Queuing Service |
| D. Stampf (BNL) | Storage System Simulator, CORBA |
| T. Wenaus (BNL) | STAR Tag Database |
| D. Morrison (BNL) | PHENIX Tag Database |
| M. Pollack (BNL) | PHENIX Tag Database, CORBA, Objecitivity |
| B. Gibbard (BNL) | RCF, HPSS, Objectivity |
| D. Olson (LBNL) | coordination |
HENP Grand Challenge Home
HPSS - High Performance Storage System
RCF - RHIC Computing Facility (overview diagram)
StAF - Standard Analysis Framework for RHIC
STAR data processing model schematic.
{kind=link}
{kind=link}
{kind=link}